2025 - 2027
MPhil in Data Science and Analytics
The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China

Hello! This is Yini Huang~
About
My name is Yini Huang(黄依妮). I am an MPhil student in Data Science and Analytics at The Hong Kong University of Science and Technology (Guangzhou), advised by Prof. Jiaheng Wei. Before that, I received my Bachelor degree from Donghua University in 2025.
I am expected to graduate from HKUST(GZ) in May 2027 and actively looking for PhD openings for Fall 2027.
My current interests include trustworthy AI and multimodal agent system. Recently, I have also been exploring Embodied-AI. Welcome to reach out for potential discussions and research collaborations.
Experience
MPhil in Data Science and Analytics
The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
BSc in Statistics
Donghua University, Shanghai, China

BFA in Fashion and Accessory Design
Donghua University, Shanghai, China
AI Data Operation Intern
AI Data Service and Operation Department
ByteDance, Shanghai, China

Data Analysis Intern
Data and Technology Department
Publicis Groupe, Shanghai, China

Publications
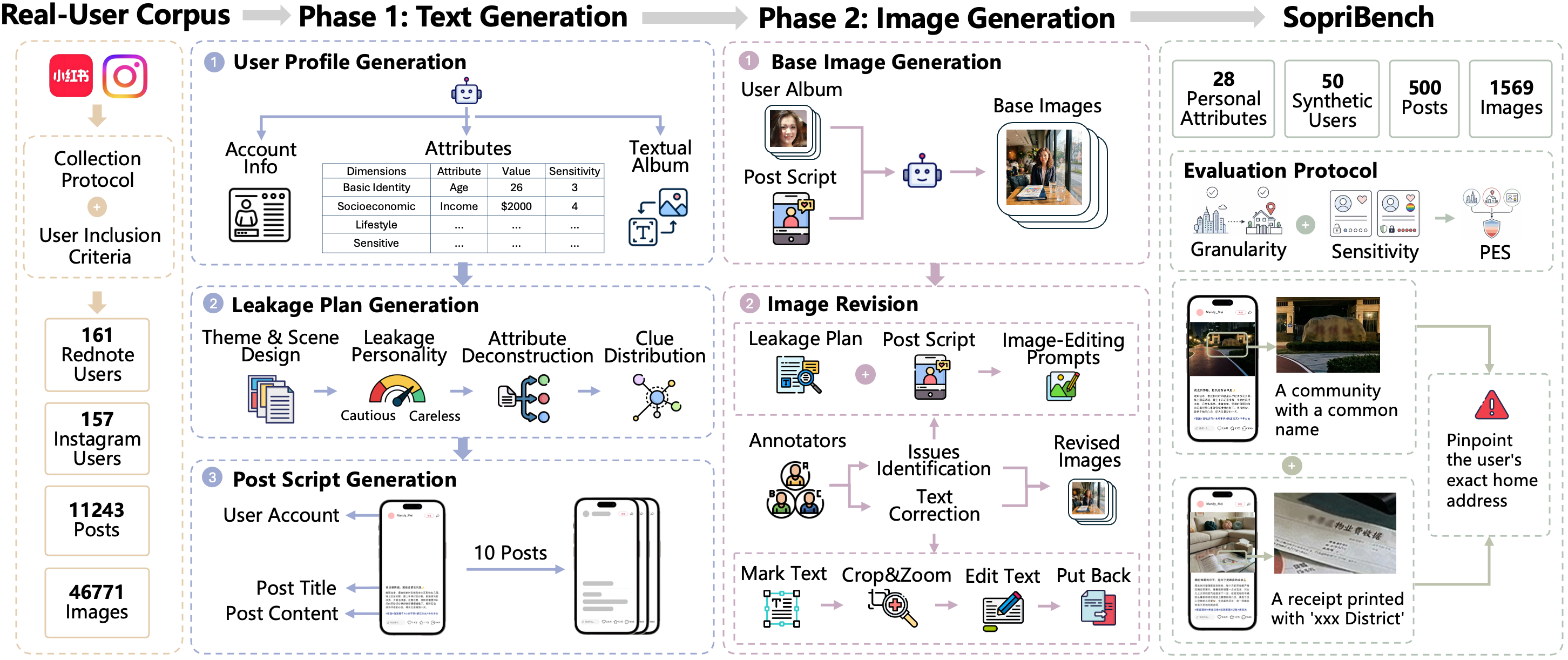
assets/publications/posts-reveal.jpg2026
Submitted to EMNLP 2026 arXiv
Public social media posts can reveal private information through weak cues scattered across text, images, or metadata. Such leakage is often cumulative and cross-post: cues that appear harmless in isolation may jointly expose a user's home, workplace, or routine. However, current research lacks a unified benchmark for user-level multimodal privacy leakage and an evaluation metric that captures exposure severity beyond binary accuracy.
To address these gaps, we propose SopriBench, a synthetic benchmark guided by leakage patterns abstracted from a private reference corpus of Rednote and Instagram accounts, covering 50 user profiles and 1,569 images with attributes, contextual sensitivity, granularity, leakage type, inference difficulty, and supporting evidence. We further introduce the Privacy Exposure Score (PES), which weights value granularity by contextual sensitivity. Inspired by abductive reasoning, we introduce Argus, a training-free agentic framework for cumulative leakage inference. Argus forms hypotheses from accumulated evidence, verifies supporting evidence, and aggregates cross-post cues into privacy profiles, achieving 0.55 PES, a 25% improvement over the strongest baseline, with the largest gain on cross-post leakage.
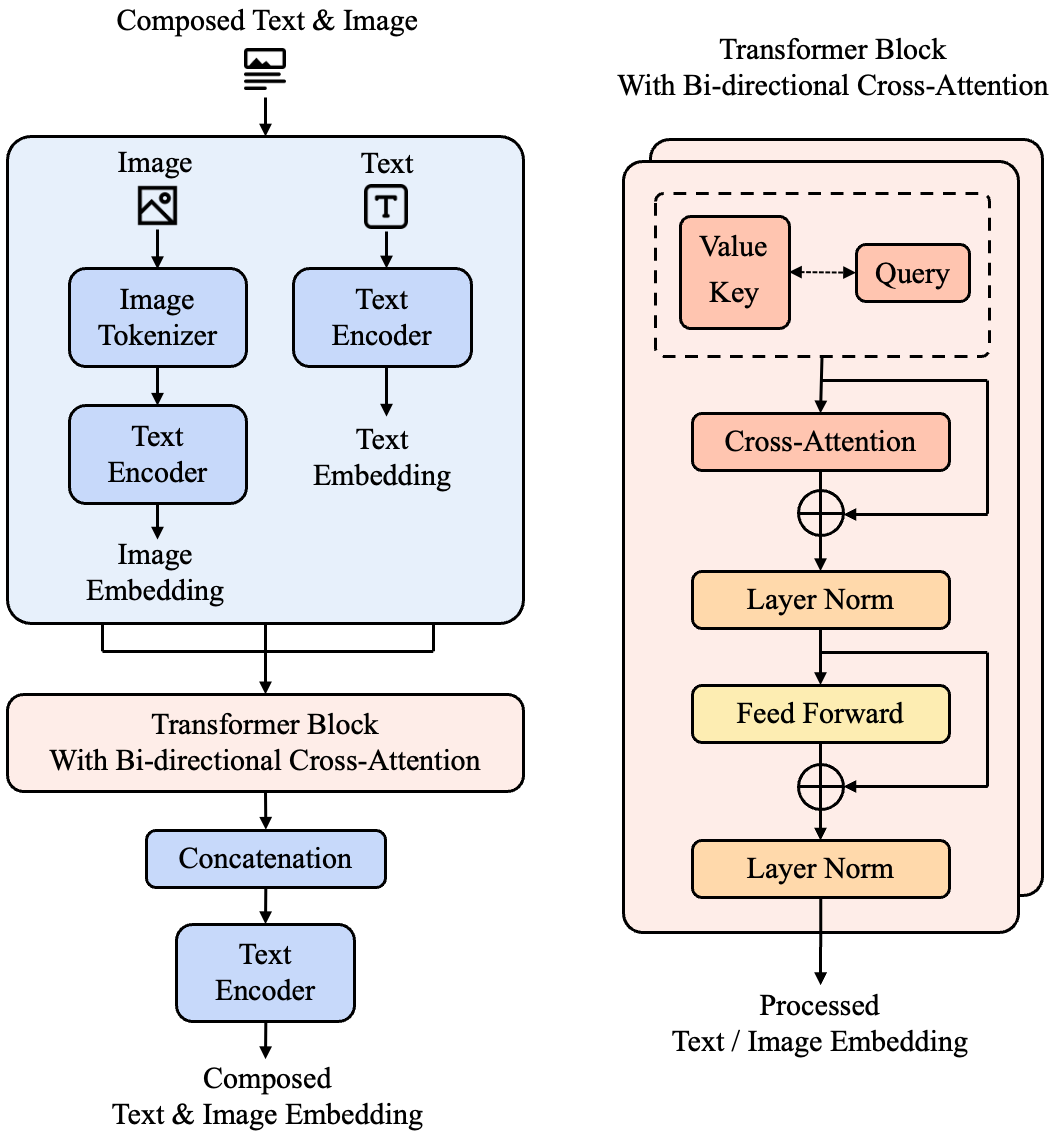
assets/publications/unica.jpg2026
Accepted by SSAIC 2026 arXiv
Multi-modal retrieval has become increasingly critical for handling the growing volume of integrated visual-textual data in real-world applications, but existing frameworks rely on implicit fusion via text encoder self-attention, limiting explicit cross-modal semantic alignment.
To address this gap, this paper proposes UniCA (Unified Cross-Attention Encoder), a multi-modal retrieval model with four key innovations: 1) a bi-directional cross-attention (Bi-CA) block that enables active semantic exchange between visual and textual tokens prior to concatenation, capturing inter-modal correlations more efficiently. 2) a Positive Similarity Loss that optimizes absolute semantic proximity between query and positive candidate embeddings. 3) a streamlined dataset UMR-S10 (Universal Multimodal Retrieval Sample 10%) to reduce computational costs while retaining semantic diversity and task representativeness. 4) an experimental validation on the WebQA benchmark demonstrates that UniCA outperforms the baseline model across Hybrid and Image-Text tasks, achieving improvements of up to 4.09% in Recall@5, 3.28% in Recall@10, and 3.96% in MRR@1 for the hybrid task. UniCA provides an efficient and robust solution for multi-modal retrieval, lowering deployment barriers through its lightweight dataset and enhanced fusion mechanism.
Projects
Ongoing
Background: This research focuses on building an emotional multimodal agent for indoor companion robot, providing domestic companion for people who live alone and need emotion support.
Key Contributions:
Next Plan: Develop the long-term memory module which aims to allow the multimodal agent to gradually learn and remember the user's lifestyle preferences and chat habits.
Ongoing
Background: Target security vulnerabilities of VLM-based Web agents such as malicious fake buttons and plug-in attacks, addressing the drawback of traditional methods only providing coarse safety judgment without attack localization and repair.
Key Contributions:
Next Plan: Enrich adversarial dataset and iteratively optimize the defense model's adaptability to diverse real-world web malicious attacks.
Sep 2025 – Dec 2025
Background: Existing IELTS oral training lacks immersive human-like interaction and standardized automated scoring, hence building avatar-based intelligent practice system aligned with official examination standards.
Key Contributions: